
![]() [a][b]
[a][b]
README : [https://github.com/HIIT/mydata-stack](https://github.com/HIIT/mydata-stack)
**Notice**
This document has been prepared by Participants of Digital Health Revolution research program and is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Implementation or use of certain elements of this document may require licenses under third party intellectual property rights, including without limitation, patent rights. The Participants of and any other contributors to the Specification are not and shall not be held responsible in any manner for identifying or failing to identify any or all such third party intellectual property rights. This Specification is provided "AS IS," and no Participant makes any warranty of any kind, expressed or implied, including any implied warranties of merchantability, non-infringement of third party intellectual property rights, and fitness for a particular purpose.
MyData Architecture defines the operations and APIs between the Operational Roles (Operator, Source, Sink etc.). Any descriptions or figures of the role’s internal structure or operations are for illustrative purposes only.
1. Introduction
Applications and services collect increasing amounts of personal data about their users, and leverage it to extract valuable knowledge about them. This information can be used for providing new services and for profiling individuals, and the results are monetizable input for e.g. targeted advertising. Unfortunately, individuals themselves typically have little or no control over how their data is created or used.
This document presents the MyData architecture, a human centric approach to liberate the potential of personal data and to facilitate its controlled flow from multiple data sources to applications and services. The simple core idea, the *individual in control of their own data*, is both a movement for digital human rights and an initiative for opening new business opportunities. It responds on a practical and technical level to individuals’ growing demand for control over their personal data and to organizations need to fulfill the requirements of tightening data protection regulation. Though both of these goals can be achieved within the current legal framework, the lack of interoperable implementations has kept them mostly a distant goal - a situation that we now want to change.
The legal framework (NOTE: In this document we use the upcoming EU General Data Protection Regulation (GDPR) as example and detail it further in a separate info box.) for protecting personal data usually starts with a freely given, specific, informed and unambiguous consent. In order for their personal data to be processed, the individual has to make a conscious choice to give consent to the external organization to process data. The consent has to be withdrawable, readable by involved trusted parties, and it should be stored in appropriate place for validity checking by the parties using or providing person’s data. This is the exact premise chosen as key guiding rule of the developed MyData model.
The architecture aims to provide a standard for implementations that
-
satisfy the legal requirements for processing of personal data and, thus, prevents unwanted and improper processing of the individual’s personal data
-
enable the individuals to easily grant and withdraw their consent for data processing
-
provide transparency to individuals about how their data is being used
-
enable flexible service creation and new business opportunities
In the following sections we present an overview of the MyData architecture (Section 2), and detail the key parts of the architecture: MyData Account (Section 3), Service Registry and Service Discovery (Section 4), Service Linking (Section 5), Authorisation (Section 6), and Data Connection (Section 7). Each detail Section has a corresponding detailed technical document (see References).
This is the third (v1.2) release of the specification and will be developed upon feedback.
|
Legal Framework for Personal Data Processing in EU
The processing of personal data is governed by legislation; for MyData architecture documentation, we use the EU General Data Protection Regulation (GDPR) as the example. A number of legal roles relating to personal data processing, most importantly the data subject, the controller, and the processor, all of which are subject to differing rights and obligations, are defined in Art. 4 GDPR. Moreover, the notion of personal data is defined as "any information relating to an identified or identifiable natural person" (the data subject) (Art. 4 (1)). Data controllers and data processors are either natural persons or legal persons, public authorities, agencies, or other bodies (Art. 4 (7)-(8)). The former means the entity which “alone or jointly with others determines the purposes and means of the processing of personal data” whereas the latter “processes personal data on behalf of the controller”. The notion of processing is wide: according to Art. 4 (2) GDPR, processing signifies “any operation or set of operations which is performed upon personal data or sets of personal data, whether or not by automated means, such as collection, recording, organization, structuring, storage, adaptation or alteration, retrieval, consultation, use, disclosure by transmission, dissemination or otherwise making available, alignment or combination, restriction, erasure or destruction”.
Processing of personal data requires a legal basis and there are several possible ones (cf. esp. Arts 6, 9 GDPR). However, from the point of view of self-determination of the data subject, consent signifies an especially important legal basis. According to the GDPR (recital 32; Art. 4 (11)), consent means an indication of the data subject’s wishes by which they signify agreement to the processing of their personal data, either by statement or by “clear affirmative action”; consent must be freely given, specific, informed and unambiguous. Article 7 GDPR provides the framework for consent: first, the controller must be able to demonstrate the existence of consent. Second, in the context of written declarations containing also other matters, consenting must be clearly distinguishable, accessible and understandable in order to be binding. Third, the data subject can always withdraw their consent and this must be as easy as consenting. The lawfulness of processing prior to withdrawal is not affected (Art. 7(3)). Fourth, in assessing the free nature of consent, particular account is to be taken of whether the performance of a contract, including provision of a service, is made conditional on the consent to processing of unnecessary data (i.e. not necessary for the performance of the contract). Prior to consenting, the data subject must be informed while duties related to information are vested on the controller (cf. e.g. Arts 12-14 GDPR). With children below the age of 16 (or depending on national level solutions all the way to the age of 13) parental oversight is required with consenting (Art. 8) in relation to information society services offered directly to a child; processing is lawful to the extent authorized. Furthermore, special categories of personal data, according to Art. 9 GDPR, include those concerning racial or ethnic origin, political opinions, religious or philosophical beliefs, and trade-union membership, as well as genetic data, and data concerning health or sex life. The processing of such data is prohibited unless one of the grounds listed in Art. 9 applies, including explicit consent. However, consent cannot legitimise all sorts of processing activities, nor can it negate obligations stemming from general principles of processing, such as purpose limitation and confidentiality (see Art. 5 GDPR). Consent does not necessarily always constitute the most appropriate ground. However, when used appropriately it enables data subjects’ control over their data. In the current MyData architecture, data transactions and processing are based on consents from data subjects, and it is possible to change or withdraw the consent at will. |
2. MyData Architecture overview
This section first summarises the core concepts from MyData Whitepaper [1] and then provides an overview of the MyData architecture by introducing the transactions, an example use case, and key related standards. The goal is to help understand systems built according to MyData principles without going too deeply in the technical implementation details; technical documentation and code release of a reference implementation of a MyData architecture is provided separately [2-6].
2.1. Core Concepts
At the heart of MyData are four operational roles and the MyData Account as shown in Figure 2.1.
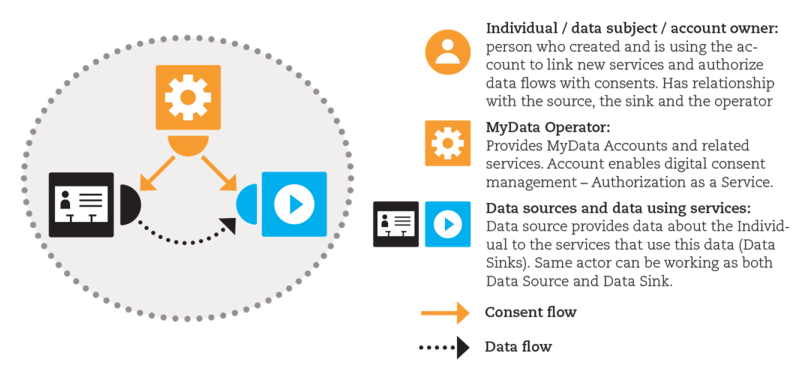
*Figure 2.1: **Four operational roles within the MyData architecture include 1) individual as the Account Owner 2) MyData Operators, 3) Sources, and 4) Sinks. The MyData Account is hosted by the Operator. Note that the flow of authorisations to use the data is separate from the flow of data.*
2.1.1. MyData Account
A key human centric concept in MyData architecture is MyData Account, which contains individual’s digital identity or identities, linked services, and authorisations. Potentially, these are complemented with individual’s other data that help in providing additional or improved services.
The Account is hosted by an independent MyData Operator, which also provides the tools for the individual to manage their account.
Finally, MyData Account also enables the user to switch Operators by taking their Account with them. Portability of the MyData Account is deferred to a later architecture release.
2.1.2. Operational Roles
There are four key operational roles in the My Data architecture: *Account Owner*, *MyData Operator*, *Source* and *Sink*. Actors (organisations and individuals) may work in one or many of the operational roles. It is e.g. very typical for an organisation to simultaneously be in the role of Source and Sink.
Account Owner is the individual who created and is using the account to link new services (see *Service Linking*) and authorise data flow (see *Authorisation*). Account Owner is usually the Data Subject as defined in Data Protection legislation. One Data Subject may have multiple accounts hosted by the same or different Operators.
Main purposes of the MyData Operator are to host MyData Accounts as well as the user interface for managing those accounts. Operator also has to provide the underlying mechanisms for linking Sources and Sinks to the account, and managing the account specific authorisations. The basic vision of the architecture enables the existence and use of multiple operators. Each individual can choose to use one or more operators to manage their authorisations.
Source is an entity that can, when authorised, provision Account Owner’s data to one or more Sinks and, correspondingly, Sink is an entity that can, when authorised, fetch data from one or more Sources and use the data to produce the agreed services. Both Sources and Sinks need to provide the corresponding MyData-compatible interfaces. Source interfaces enable the management of data provisioning, while Sink interfaces enable the management of data usage. It is quite common that a service is working both as Source and Sink, and providing, therefore, both Sink and Source capabilities and interfaces.
2.1.3. Mapping the operational roles with legal roles
For clarity, it is important to map the operational roles Account Owner, Source and Sink with the corresponding legal roles - Data Subject, Data Controller and Processor. The GDPR legal framework only covers cases of personal data where the Data Subject is a natural person, but the MyData architecture technically may be used also for managing other data.
When the Account Owner is a natural person and their data is being processed, the Account Owner is the Data Subject. The other legal roles in MyData system can be then determined by answering two questions:
-
Who determines the purposes and means of the processing of personal data?
-
Who actually processes the data?
Two typical cases as shown in Figure 2.2 are:
Delegation With Account Owner’s consent, Sink accesses personal data from the Source and processes it for the defined purpose. In this case, both the Source and the Sink are in legal terms Data Controllers.
Repurposing Service is processing personal data for a specified purpose within its own scope - at some point the service may suggest for the Account Owner a new purpose or means of processing data. In this case the Service is in legal terms the Data Controller.
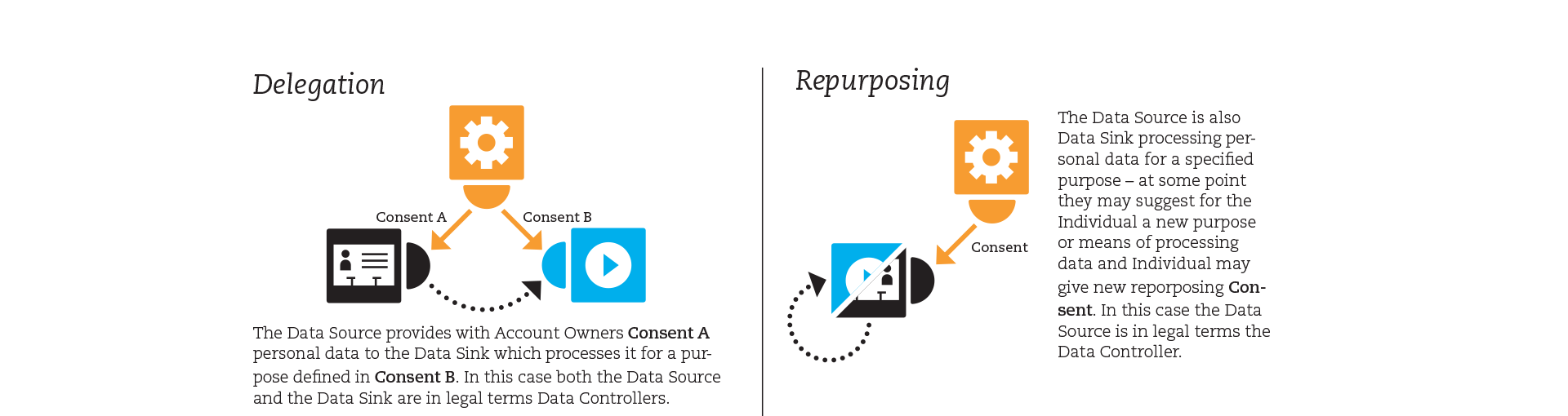
*Figure 2.2: Examples how MyData approach can support different kinds of data flow use cases such as delegation and repurposing.*
Image captions <https://github.com/HIIT/mydata-stack/issues/3>
2.2. Use Case of this Architecture
This example use case is presented to illustrate the possibilities of MyData architecture. The case covers a scenario, where *Alice* authorises a new service *(*imaginary service *Balance)* to access her data from other compatible services *(*imaginary services* Fresh Lunch and TrackMe)* using her Operator (imaginary service *MyData Link)*. Currently delegation is the only use case handled throughout the architecture related specifications and reference implementations. Other use cases are deferred to future architecture releases.

Balance is MyData compatible and, thus, it asks Alice, if she already has a MyData Account with which to *link*, or if she would be interested in creating a new account with a recommended operator. Alice picks the ‘Link existing account’ choice and authenticates to her account at MyData Link from within the Balance app.
The Balance app then suggests that Alice links also her activity tracker and restaurant bill data, as access to these would improve the use of the app. However, Balance can be used also without these enriching data sources. By using the embedded MyData Link user interface within the Balance app, Alice *authorises* the Balance app to access her data from TrackMe, but leaves the restaurant bills out.
Later Alice logs in to her operator MyData Link and sees that the recently connected Balance app now appears on the list of her services. User Interface of the MyData Link operator has functionality for *discovering* compatible services amongst those the operator has on its service listing. With that Alice finds out that Balance app could also use data from the Fresh Lunch restaurant chain. Alice decides to subscribe to Fresh Lunch’s loyalty program, link Fresh Lunch to her account at MyData Link, and authorises the Balance app to access her restaurant bill data.
After authorizations are granted, the Balance app fetches the data from the API interfaces offered by TrackMe and and Fresh Lunch using a *data connection*. Balance app then uses Alice’s data to provide infographics of her nutritional behaviour versus her current health state and targets.
2.3. Transactions
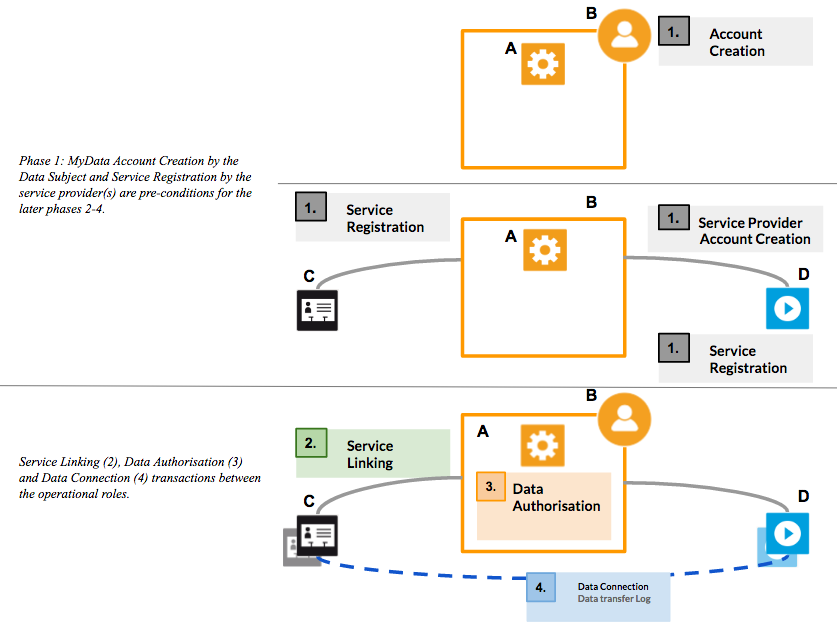
At the highest level there are four sequential (always executed strictly in order listed below) transaction types between Sources, Sinks and the Operator as shown in Figure 2.3:
**1. Account Creation and Service Registration: **Prerequisites for linking new services to an Account are that the Data Subject has created an Account at Operator and that the service to be added has been registered in the Operator’s service registry. Service Registration is discussed in [Section 4](#heading=h.ycmyid1smpqb).
**2****. ****Service Linking:** Account Owner links a new Source or Sink to their MyData Account. Only services that are linked to an Account can be authorised. Service Linking is discussed in [Section 5](#heading=h.4g32twnc431z). Account Owner can discover compatible services to link by using Operator’s Service Discovery functionality, which is discussed in [Section 5.3](#heading=h.nuq9go3mlaoe).
**3. ****Authorisation:** Account Owner authorises a specific Source to provide her data for a specific Sink and the Sink to use that data or a service to further process data it already has. In this architecture version all Authorisations are consent-based. Authorisation is discussed in [Section 6](#heading=h.pdnyzu9te7y6).
**4. Data Connection:** Sink requests data from a Source, relying on the acquired authorisation. Data Connection is discussed in [Section 7](#heading=h.q1yusgvt7c2k).
*Figure 2.4: Key related standards.*
The development of MyData architecture has been influenced by many existing and upcoming standards, specifications, and questions raised from reading them. Of particular importance are OAuth 2.0, User Managed Access (UMA) and OpenID Connect as well as the upcoming Kantara Initiative’s Consent Record specification (abbreviated here and in other MyData technical specifications as KI-CR). When applicable, we have used the existing technologies and terminology, but in some areas we have simplified the solution to better suit our needs.
Our authorisation is based on a centralized authorisation server similar to UMA. The fact that resource servers and clients are always discoverable and trusted via their registration to the service registry enables our authorisation flow to require fewer messages compared to full UMA flow as we no longer need to introduce the parties to each other in the beginning of authorisation.
The authorisation mechanism used in this architecture is similar to OAuth 2.0 Authorisation Code flow model as the communication is expected always to happen between secure servers. No other flows are supported. A strong conceptual difference is in defining Resource Sets that are finally to be authorised: Resource Set Registration is initiated in our architecture by the Resource Owner at the time of authorisation transaction, not a priori by the Resource Server.
We use JSON Web Token and JSON Web Key from OpenID Connect’s model to authenticate each party (RS, AS, client, Service Registry) involved in the message exchange. Also, OpenID Connect related Identity provider & federation models for arranging the assurance levels and trust network required in the background is currently work-in-progress.
Consent and assignment registry and related digital proofs (transaction records) are built on the upcoming Minimum Viable Consent Receipt specification, a work evolving in Kantara Initiative’s CISWG.
W3C’s Data Catalog vocabulary and The RDF Data Cube Vocabulary are used in Service Registry specification. Both of these vocabularies are published as W3C Recommendation 2014 and they are developed for increasing findability of datasets and data items, and interoperability between datasets. They enable authorisations to be used only between compatible services.
3. MyData Account
Functionally, MyData Account is the key enabler in authorising, controlling and logging the data flow between multiple services. It keeps track of individual’s consents and other relevant information in a single place thus providing a unified view to all the Authorisations of data flows. Also, it makes it easier for the individual to manage the flows as they are all defined with the same tools, which makes it easier to compare different Authorisations.
Typically, MyData Account constain
-
basic information about the Account Owner, e.g. contact detail, preferences etc
-
individual’s identities for both single sign-on (SSO) uses and for managing the Service Links and consents. Depending on the implementation, Account could hold just the public keys or both the public and private keys. Naturally, hosting private keys poses more stringent security requirements for the Operator.
-
individual’s Service Links and Authorisations as well as their respective Status Records
To be operational, the Account has to be hosted by a MyData Operator. It is expected that most of the operator services will be provided by organisations, though it is also possible for individuals to run the operator software themselves thus becoming self-operators. The key difference is that organisations can potentially provide additional trust, assurance and security levels compared to a self-operator. Acceptance and audit process for an organization wishing to serve as a trusted operator are beyond the scope of this document (NOTE: It is likely to be defined along extending the criteria set for entering e.g. a regional or governmental trust network - ISO/IEC 29115 entity authentication assurance level or FICAM TFS are examples of trust and assurance level related requirements that may apply.).
The information in a MyData Account is designed for portability allowing the individual to change operators by taking their account with them. The implementation of portability as a service between Operators is deferred to a later architecture release.
More detailed technical information about the MyData Account can be found in the MyData Account specification [2].
4. Service Registration and Service Discovery
Service Registry is part of the Operator and it provides two major functions: it maintains a database of all services accessible with this Operator (Service Registration) and it enable searching for compatible services (Service Discovery) both for the Account Owners using the services and for the developers of services. This section first introduces the different service descriptions used with the registry and then goes over the Service Registration and Service Discovery processes. More detailed technical information about the Service Registry can be found in the MyData Service Registry technical specification [3].
4.1. Service Description
For efficient service management, discovery, and matching, each service needs to be described in the Service Registry. In addition to the compulsory description data such as service ID and some promotional material e.g. service logo, a Service Description is an aggregation of multiple levels of service descriptions as shown in Figure 4.1:
-
a Human Readable Description forms a basis for promoting and introducing the services to Account Owners
-
a set of Technical Descriptions on the service interface functionalities need to be introduced in order to provide tools for service interoperability
-
Service Data Description is required for intelligent service discovery and matching
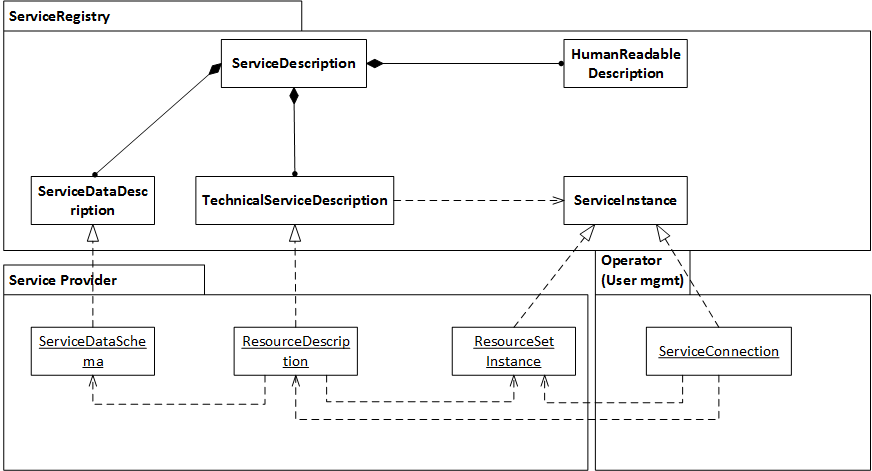
*Figure 4.1: Realization of a service registration*
4.1.1. Human Readable Description
A basic Service Description contains a unique service ID, a human readable textual presentation of the service, and possible material (logo etc.) for promoting the service. These are used in various stages for presenting the service and its data in a non-technical, end-user friendly way, such as in the service store, where the Account Owner can discover services. The idea for the Human Readable Descriptions on both the service functionality and the data the service collects or manages is that the Account Owner or the developer trying to link the particular service to his own ecosystem can easily get an overview of the concept.
4.1.2. Technical Service Description
The Technical Service Description is a document required only for Source services. It presents the technical API for accessing a particular resource. This document can be, for example, a WADL document presenting the API of a REST-style resource interface. WADL (Web Application Description Language) is a machine-readable XML description of HTTP-based web applications. The API is then implemented by one or more data resource instances or service instances. Each service provider specific instance is given an unique ID, which in combination with instance’s unique address enable service linking (Section 5), authorisation management (Section 6) and data access (Section 7).
4.1.3. Service Data Description
Service Data Description presents the data provided through the service, and it enables finding relevant Sources based on different criteria. For service developers, it supports finding and integrating relevant Sources to a Sink, and for Account Owners it facilitates making recommendations about relevant Sources and Sinks. The description enables defining, what data elements are offered by a Source or required by a Sink. This information is also needed when showing to an end user, what kind of data elements are available in a Source, which the Account Owner uses in deciding, which data elements are made available to a Sink.
Service Data Description defines metadata about data of a service. It includes general metadata such as title, description, subject and publisher. In addition, it describes what kind of data a Source produces and from where and in which format it is available. A Service Data Description for a Sink describes what kind of data it uses and needs.
Linking of metadata elements to Linked Data and common classification schemes is also supported. The purpose is to establish a common understanding of various data elements, to enable correct interpretation of the data, to enable searching of data based on different criteria and relations of data elements, and to enable utilization of data in new services and applications.
Different functionalities such as data transformations, semantic enrichment, and mapping of data elements are needed to support service providers in creating and validating semantic service descriptions. The descriptions are collected when Sources and Sinks are registered in a Service Registry.
[a]Testataan haittaavatko kommentit markdownin generoimista html:ksi? [b]kommentit eivät menoa haittaa